
klish3.en.md 100 KB
The klish program is designed to organize the command line interface, in which only a strictly defined set of commands is available to the operator. This distinguishes klish from standard shell interpreters, where an operator can use any commands existing in the system and the ability to execute them depends only on access rights. The set of commands available in klish is defined on configuration step and can be set, in general, in a variety of ways, The main ones are XML configuration files. Commands in klish are not are system commands, and are fully defined in the configuration files, with all possible parameters, syntax, and actions that they fulfillment.
The main application of klish is in embedded systems where the operator has access to only certain, device-specific commands, not arbitrary set of commands, as in general-purpose systems. In such embedded klish systems can replace the shell interpreter, which is not available to the of the operator.
An example of embedded systems is managed networking equipment. Historically, there have been two main approaches to organization in this segment command line interface. Conventionally, they can be called the "Cisco" approach and the "Cisco" approach "Juniper. Both Cisco and Juniper have two modes of operation - command mode and configuration mode. In command mode, the entered commands are immediately are executed but do not affect the system configuration. These are view commands status, commands to control the device, but not to change its configuration. In configuration mode the hardware and services are being configured. In Cisco, the configuration commands also are executed immediately, changing the system configuration. In Juniper, the configuration can be conventionally represented as a text file, changes in which are are performed using standard editing commands. When editing the changes are not applied to the system. And only by special command the entire The accumulated set of changes is applied at once, thus ensuring that change consistency. With the Cisco approach, similar behavior can also be emulate by designing commands in a certain way, but for Cisco, it's less of a the natural way.
Which approach is better and easier in a particular case is determined by the task. Klish is primarily designed for the Cisco approach, i.e., immediately executable teams. However, the project has a plugin system, which allows you to extend it capabilities. So the plugin klish-plugin-sysrepo, implemented by a separate project, Powered by sysrepo storage, it allows you to organize the Juniper approach.

The klish project uses a client-server model. Listening server klishd loads the command configuration and waits for requests from clients on the UNIX socket (1). On a connection from a client, the klishd listening server spawns (fork()) a separate process (2), which will be concerned with serving one particular customer. The spawned process is called the klishd serving server. Listening server klishd continues to expect new connections from clients. Interaction between clients and the serving server are carried out over UNIX sockets using the KTP (Klish Transfer Protocol), which is specially designed for this purpose (3).
The client's task is to transmit input from the operator to the server and receive it from the server the result to be shown to the operator. The client does not know what commands exist, how to execute them. The execution is handled by the server side. Since the client has relatively simple code, it is not difficult to implement alternative programs - clients, such as a graphical client or a client for automated controls. Right now, there is only a text-based command line client called klish.
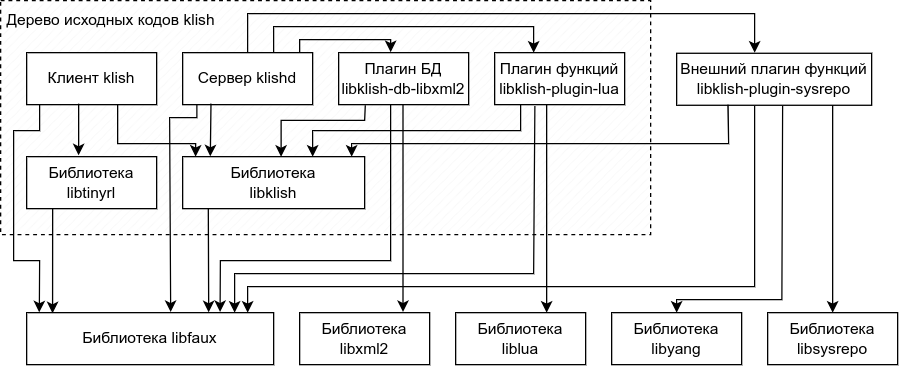
The basis of the klish project is the libklish library. The klish client is based on it and klishd server. The library implements all basic mechanisms of work and interactions. The library is part of the klish project.
The text client uses another built-in library, the libtinyrl (Tiny ReadLine). The library provides interaction with the user when working on the command line.
All executable files of the klish project, as well as all its built-in libraries use the libfaux (Library of Auxiliary Functions) library in their work - library of auxiliary functions. In previous versions of the project klish library was part of the klish source code, now it has been separated into a separate project and includes functions that make it easy to work with strings, files, networking, standard data structures, etc. The libfaux library is a mandatory external library a dependency for the klish project.
In addition, klish plugins, discussed below, can also use the other libraries for their work.
Klish has two types of plugins. Plugins for loading command configurations (let's call them database plugins) and plugins that implement actions to commands from the user (let's call them function plugins). Klish does not has built-in commands and means of loading configuration (except for a special ischeme cases). All this functionality is implemented in plugins. Several plug-ins with basic functionality are included in the source codes of klish and are located in the "dbs/" and "plugins/" directories.
All necessary plugins are loaded by the klishd listening server at the beginning of its operation. What kind of plugins to load custom command configurations are needed use it learns from its base configuration file (a special file in the INI format). The klishd server then uses the database plugin to load the configuration of user commands (e.g. from XML files). From this configuration, it learns the list of required function plug-ins, and so loads the these plug-ins into memory. However, using functions from function plug-ins will only serving (not listening to) the klishd server on requests from the user.
The configuration file is used to configure the klishd server parameters
/etc/klish/klishd.conf. An alternate configuration file can be specified at
to start the klishd server.
The configuration file is used to configure the client parameters
/etc/klish/klish.conf. An alternate configuration file can be specified at
launching the klish client.

The internal representation of the command configuration in klish is kscheme. Kscheme is. is a set of C-structures representing the entire tree of commands available to the user, visibility areas, parameters, etc. It is by these structures that the all internal work - command search, autocompletion, generation of hints at user interaction.
In klish there is an intermediate representation of the command configuration in the form of C-structures, called ischeme. This representation is similar to kscheme in general, but differs from it in that all configuration fields are represented in text form, all references to other objects are also text object names, on the that are referenced, rather than pointers as in kscheme. There are other differences as well. Thus ischeme can be called an "uncompiled schema" and kscheme can be called an "compiled". "Compilation", i.e. conversion of ischeme to kscheme is produced by the internal mechanisms of klish. Ischeme can be manually set by the user in the form of C-structures and assembled as a separate database plugin. In this case no other database plugins will be needed, the entire configuration is already ready to be converted to kscheme.
As part of klish (see dbs/), the following database plugins exist for downloading command configurations, i.e., schematics:
- expat - Uses the expat library to load configuration from XML.
- libxml2 - Uses the libxml2 library to load configuration from XML.
- roxml - Uses the roxml library to load configuration from XML.
- ischeme - Uses the configuration built into C code (Internal Scheme).
All database plugins translate an external configuration obtained e.g. from a XML files, to ischeme. In the case of ischeme, the additional conversion step is not is required, since the ischeme is already in place.
The installed dbs plugins are located in /usr/lib (if configuring the
assembly with --prefix=/usr). Their names are libklish-db-<name>.so, e.g.
/usr/lib/libklish-db-libxml2.so.
Each klish command performs an action or several actions at once. These actions need to be described somehow. If we look inside the implementation, klish can only run executable compiled code from the plugin. Plugins contain so-called symbols (symbol, sym), which, in fact, represent are functions with a single fixed API. These symbols can be referenced by klish commands. In turn, a symbol can execute complex code, e.g. run the shell interpreter with the script defined in the command description klish in the configuration file. Alternatively, another character can execute a Lua script.
Klish only knows how to get symbols from plugins. Standard symbols are implemented in the plugins included in the klish project. The klish project includes the following plug-ins:
- klish - Basic plugin. Navigation, data types (for parameters), auxiliary functions.
- lua - Execution of Lua scripts. The mechanism is built into the plugin and does not use an external program for interpretation.
- script - Execution of scripts. Takes shebang into account to determine which interpreter to use. In this way, not only shell scripts, but also scripts in other interpreted languages. By default the shell interpreter is used.
Users can write their own plugins and use their own characters in the
klish commands. Installed plugins are located in /usr/lib.
(if configuring the build with --prefix=/usr). Their names are
libklish-plugin-<name>.so, such as /usr/lib/lib/libklish-plugin-script.so.

Symbols are "synchronous" and "asynchronous". Synchronous characters are executed in the klishd address space, a separate process is spawned for asynchronous ones.
Asynchronous symbols can accept user input (stdin) as input, received by the klishd server from the client via the KTP protocol and sent to the spawned process within which the asynchronous process is executed symbol. In turn, asynchronous symbol can write to stdout, stderr streams. The data from these streams is received by the serving server klishd and forwarded to the to the client via the KTP protocol.
Synchronous characters (with output to stdout, stderr) cannot receive data through the stdin input stream, since they are executed within the serving server klishd and, for the duration of the symbol code execution, other server functions are temporarily stopped. Receiving data from the customer is stopped. The attendant klishd server is a single-threaded program, so synchronous characters must be use with caution. If the symbol takes too long to execute, then the server will hang for that time. In addition, synchronous characters are executed in the of the server's address space. This means that the execution of an unreconfigured character containing errors may cause the serving server to crash. Although a synchronous symbol does not have a stdin input stream, it can use the output streams stdout, stderr. To get data from these streams and The service server spawns a service server to send them to the client. A process that receives and temporarily stores data coming from a symbol. When when the symbol execution is completed, the service process forwards the saved data back to the serving server, which in turn sends them to the client. Synchronous characters are recommended only when the character changes the state of the serving server and therefore cannot be executed as part of the of another process. For example, section navigation (see Scopes) is realized by a synchronous symbol, because the user's position in the section tree is stored in the serving server.
Lightweight synchronous symbols have no input and output data streams stdin, stdout, stderr. Due to this, execution of such a symbol does not require generation of new processes, as it is done in the case of ordinary synchronous symbol, or an asynchronous symbol. Thus a lightweight synchronous symbol is executed as quickly as possible. Although the lightweight synchronous symbol does not have a of the stdout stream, it can generate an output text string. The string is formed manually and, with the help of a special function, is passed to to the serving server, which can send it to the client as stdout. Otherwise, the lightweight synchronous symbol has the same features as the regular one synchronized character. It is recommended to use lightweight synchronous characters when the fastest possible execution is required. An example of such a task can serve as a prompt for the user. This is a service function that is executed every time the user presses the button Input. Another example of usage is the function to check whether the the argument entered by the user is valid (see PTYPE), as well as functions to formation of autocompletion and hints.
A symbol, or, more correctly, a klish command, since a command may consist of a several consecutively executed characters, may be regular or to be a filter. For simplicity, let's assume that the command performs only one symbol, and so we will talk about symbols rather than commands. A common symbol performs some useful action and, often, produces some output text output. And the filter receives as input the result of work, i.e., in this case case, the text output of a regular character and processes it. To specify that a filter must be applied to an ordinary command, the user uses chains of commands separated by "|". In many ways it is similar to chains in the standard a custom shell.

Synchronous symbols have no stdin input stream, i.e., they do not receive an input of no data and therefore cannot be full-fledged filters, but can be be used only as the first command in a chain of commands. Lightweight synchronous characters do not have and output stream stdout, so they cannot be use not only as filters, but also as the first place team in the chain of command commands, because the filter will not be able to get any data from them. Typical the use of lightweight synchronous characters are service internal functions, that do not interact directly with the user and are not used in chains commands.
The first command in the command chain receives stdin stream input data from user, if required. Let's call the stdin stream from the user - by the global stdin stream. Then the stdout stream of the previous character in the chain is received at the input of the stdin stream of the next character. Output stream stdout The last character in the chain is considered to be global and is sent to the servicer. to the server and then to the user.
Any character in the chain has the ability to write to the stderr stream. The entire chain a single stderr stream, i.e. one for all symbols. This stream is considered to be global stderr and is sent to the serving server and then to the user.
The number of commands in the command chain is unlimited. The klish command must be is declared as a filter so that it can be used after the "|" sign.
KTP (Klish Transfer Protocol) is used for client interaction klish with service by the klishd server. The main task is to transfer commands and user input from the client to the server, transmitting the text output of the executed command and status of command execution - in the opposite direction. In addition, the protocol provides for means for the client to obtain autocomplete options from the server for the incomplete commands and hints for commands and parameters.
The KTP protocol is implemented by means of the libfaux library, which simplifies the creation of a specialized network protocol on the basis of a generalized template network protocol. The protocol is built on top of a streaming socket. Currently in the project klish uses UNIX sockets for client-server communication.
A KTP protocol packet consists of a fixed-length header and a set of "parameters". The number of parameters is stored in a special header field. Each parameter has its own little header that specifies the type of parameter and the its length. Thus, at the beginning of a KTP packet is the KTP header, followed by the KTP first parameter header, first parameter data, second parameter header parameter, data of the second parameter, etc. All fields in the headers are passed with using network (big-endian) byte order.
KTP header:
| Size, bytes | Field name | Field value |
|---|---|---|
| 4 | Magic number | 0x4b545020 |
| 1 | Protocol version (major) | 0x01 |
| 1 | Protocol version (minor) | 0x00 |
| 2 | Command code | |
| 4 | Status | |
| 4 | Not used | |
| 4 | Number of parameters | |
| 4 | The length of the entire packet (with header) |
Command codes:
| Code | Name | Direction | Description |
|---|---|---|---|
| 'i' | STDIN | -> | stdin user input (PARAM_LINE) |
| 'o' | STDOUT | <- | stdout command output (PARAM_LINE) |
| 'e' | STDERR | <- | stderr command output (PARAM_LINE) |
| 'c' | CMD | -> | Execute command (PARAM_LINE) |
| 'C' | CMD_ACK | <- | The result of the command |
| 'v' | COMPLETION | -> | Request for autocompletion (PARAM_LINE) |
| 'V' | COMPLETION_ACK | <- | Possible additions (PARAM_PREFIX, PARAM_LINE) |
| 'h' | HELP | -> | Prompt (PARAM_LINE) |
| 'H' | HELP_ACK | <- | Hint (PARAM_PREFIX, PARAM_LINE) |
| 'n' | NOTIFICATION | <-> | Asynchronous message (PARAM_LINE) |
| 'a' | AUTH | -> | Authentication Request |
| 'A' | AUTH_ACK | <- | Authentication Confirmation |
| 'I' | STDIN_CLOSE | -> | stdin was closed |
| 'O' | STDOUT_CLOSE | -> | stdout was closed |
| 'E' | STDERR_CLOSE | -> | stderr was closed |
The "Direction" column shows in which direction the command is transmitted. Arrow right arrow means transfer from client to server, left arrow means transfer from server to the client. In the "Description" column in brackets are the names of parameters in which data is being transmitted.
The status field in the KTP header is a 32-bit field. Bit values status fields:
| Bit Mask | Bit Name | Value |
|---|---|---|
| 0x00000001 | STATUS_ERROR | Error |
| 0x00000002 | STATUS_INCOMPLETED | Command execution not completed |
| 0x00000100 | STATUS_TTY_STDIN | stdin client is terminal |
| 0x00000200 | STATUS_TTY_STDOUT | stdout client is terminal |
| 0x00000400 | STATUS_TTY_STDERR | stderr client is a terminal |
| 0x00001000 | STATUS_NEED_STDIN | Command accepts user input |
| 0x00002000 | STATUS_INTERACTIVE | The output of the command is for the terminal |
| 0x00010000 | STATUS_DRY_RUN | Idle start. Don't execute the command |
| 0x80000000 | STATUS_EXIT | Ending session |
Parameter header:
| Size, bytes | Field name |
|---|---|
| 2 | Parameter type |
| 2 | Not used |
| 1 | Parameter data length (without header) |
Parameter types:
| Code | Name | Direction | Description |
|---|---|---|---|
| 'L' | PARAM_LINE | <-> | String. Multifunctional |
| 'P' | PARAM_PREFIX | <- | String. For autocomplete and hint |
| '$' | PARAM_PROMPT | <- | String. User prompt |
| 'H' | PARAM_HOTKEY | <- | Function key and its meaning |
| 'W' | PARAM_WINCH | -> | The size of the user window. When changing |
| 'E' | PARAM_ERROR | <- | String. Error message |
| 'R' | PARAM_RETCODE | <- | Return code of the executed command |
From the server to the client, along with the command and the parameters corresponding to the command, can be passed additional parameters. For example, with the CMD_ACK command, that reports the completion of a user command can be sent to the PARAM_PROMPT parameter, which tells the client that the user's the invitation has changed.
The main way to describe klish commands today is XML files. In this section, all examples will be based on XML elements.
Commands are organized into "scopes" called VIEWs. That is, each command belongs to a VIEW and is defined in it. When working in klish always there is a "current path". By default, when starting klish the current path is is assigned to a VIEW named "main". The current path determines which commands are currently are visible to the operator at the moment. The current path can be changed navigation commands. For example go to a "neighboring" VIEW, then the current path will be this neighboring VIEW, displacing the old one. Another possibility is to "go deep inside", i.e. to go into a nested VIEW. The current path will then become a two-level path, similar to how you can enter a subdirectory in the file system. When the current path has more than one level, the operator has access to the commands of the "deepest" VIEW, as well as commands of all the of the above levels. You can use navigation commands to exit from nested levels levels. When the current path is changed, the navigation command used determines whether the whether the VIEW of the current path is superseded by another VIEW at the same nesting level, or the new VIEW will become nested and another level will appear in the current path. The way VIEWs defined in XML files do not affect whether a VIEW can be nested.
When defining VIEWs in XML files, some VIEWs can be nested within other VIEWs. This nesting should not be confused with the nesting when the current path is formed. A VIEW defined within another VIEW adds its commands to the commands of the of the parent VIEW, but can also be addressed separately from the parent VIEW. In addition to this, there are references to VIEWs. By declaring such a link inside a VIEW, we add the commands of the referenced VIEW to the commands of the current VIEW VIEW. You can define a VIEW with "standard" commands and include a reference to the this VIEW into other VIEWs that require these commands without redefining them.
In XML configuration files, the VIEW tag is used to declare a VIEW.
Commands (tag COMMAND) can have parameters (tag PARAM). A command is defined by
within a VIEW and belongs to it. Parameters are defined within the command
and, in turn, belong to it. A command can consist of only one word,
unlike the commands in klish of previous versions. If you want to define a verbose
command, then nested commands are created. I.e. within the command identified by
the first word of a verbose command, a command identified by the
to the second word of a verbose command, etc.
Strictly speaking, a command differs from a parameter only in that its value can be can only be a predefined word, while the value of a parameter can be be anything. Only the type of the parameter determines its possible values. Thus so the command can be thought of as a parameter with a type that says that the valid value is the parameter name itself. Internal implementation teams are exactly like that.
In general, a parameter can be defined directly in VIEW rather than internally teams, but this is more of an atypical case.
Like VIEW, commands and parameters can be references. In this case, the reference can be consider it simply as a substitution of the object pointed to by the reference.
Parameters can be mandatory, optional, or mandatory selection among several candidate parameters. Thus, when entering the command some parameters may be specified by the operator and some may not. When parsing The command line is used to compose a sequence of selected parameters.
The type of a parameter defines the allowed values of that parameter. Usually types
are defined separately using the PTYPE tag, and the parameter refers to a specific
type by its name. The type can also be defined directly inside the parameter, but this is
is not a typical case, since standard types can cover most of the
Needs.
The PTYPE type, like a command, performs a specific action specified by the tag
ACTION. The action specified for the type checks the value entered by the operator
parameter and returns the result - success or error.
Each command must define the action to be performed when that command is entered
operator. The action can be a single action, or multiple actions for a single command.
The action is declared with the ACTION tag inside the command. ACTION specifies a reference
to the symbol (function) from the function plugin that will be executed in this case.
All data inside the ACTION tag is available to the symbol. The symbol can at its own discretion
use this information. As data, for example, it can be set to
script to be executed by the symbol.
The result of the action is a "return code". It defines the success or failure to execute the command as a whole. If a command is defined for one command more than one action, then calculating the return code becomes more complex Task. Each action has a flag that determines whether the return code affects the of the current action to a common return code. Actions also have settings, determining whether the action will be executed if the previous action is executed ended with an error. If several actions are performed sequentially, that have an influence flag on the common return code, then the common return code will be the code the return of the last such action.
Filters are commands that process the output of other commands.
The filter can be specified on the command line after the main command and the | sign.
The filter cannot be a stand-alone command and can be used without the main
commands. An example of a typical filter is the UNIX analog of the grep utility.
Filters can be used one after the other, with a | separator like this
is done in the shell.
If the command is not a filter, it cannot be used after the character
|.
The filter is specified in the configuration files using the FILTER tag.
SWITCH and SEQ containers are used to aggregate nested parameters and define the rules by which the command line is parsed with respect to of these parameters.
By default, it is assumed that if a command is defined sequentially within a command several parameters, then all these parameters must also be consistently to be present on the command line. However, sometimes there is a need for the operator has entered only one parameter of his choice from the set of possible parameters. In such a case, the SWITCH container can be used. If, when parsing a command SWITCH container is found inside the command, then to match the only one parameter must be selected for the next word entered by the operator from the parameters nested in SWITCH. I.e. with the help of the SWITCH container there is branching parsing.
The SEQ container defines a sequence of parameters. All of them must be are consistently mapped to the command line. Although, as noted earlier, The parameters nested in the command are already parsed sequentially, however The container may be useful in more complex designs. For example, a container The SEQ itself can be an element of a SWITCH container.
To generate the command line prompt that the operator sees,
The PROMPT construct is used. The PROMPT tag must be nested inside a VIEW.
Different VIEWs can have different invitations. I.e. depending on the current
paths, the operator sees a different invitation. The invitation can be dynamic
and generated by the ACTION actions specified within PROMPT.
For operator convenience, commands and parameters can be realized for commands and parameters
hints and autocomplete. Hints (help), which explain the purpose of and
format of possible parameters, are displayed in the klish client by pressing the key
?. The list of possible additions is printed when the operator presses the Tab key.
To set hints and a list of possible add-ons in the configuration, the following are used
HELP and COMPL tags. These tags must be nested relative to
of the corresponding commands and parameters. For simplicity, the prompts for a parameter or
commands can be specified by the main tag attribute if the hint is a
is static text and does not need to be generated. If the tooltip is dynamic, then
its contents are generated by ACTION actions nested inside HELP. For
of COMPL additions of ACTION actions generate a list of possible values
parameters separated by a line feed.
Commands and parameters can be hidden from the operator based on dynamic
conditions. A condition is specified using a COND tag nested inside a COND tag
of the corresponding command or parameter. Within a COND are one or more
ACTION actions. If the ACTION return code is 0, i.e. success, the parameter is available
operator. If ACTION returned an error, the element will be hidden.
The klishd process does not load all existing feature plugins in a row, but only the
those specified in the configuration using the PLUGIN tag. Data inside the tag
may be interpreted by the plugin initialization function as it sees fit,
particularly as a configuration for a plugin.
For the operator's convenience, "hot keys" can be set in the klish command configuration.
keys". The tag for specifying hotkeys is HOTKEY. List of hotkeys
is passed by the klishd server to the client. It is at the discretion of the client to use this
information or does not use it. For example, for an automated control client
hotkey information is meaningless.
When defining a hotkey, a text command is specified, which should be executed when a hotkey is pressed by the operator. This can be a quick display the current device configuration, exit the current VIEW, or any other command. The klish client "catches" hotkey presses and transmits them to the server command corresponding to the pressed hotkey.
Some tags have attributes that are references to other tags that are defined
In configuration files, elements. For example, VIEW has a ref attribute, with the help of the
which creates a "copy" of the third-party VIEW at the current location in the schema. Or the tag
PARAM has a ptype attribute, which is used to refer to PTYPE, defining the
parameter type. Klish has its own "language" for organizing references. You can
to say it is a highly simplified analog of file system paths or XPath.
The path to an element in klish is typed by specifying all of its parent elements with the
separator /. The name of an element is the value of its name attribute. Path
also starts with the / character, indicating the root element.
Relative paths are not supported at this time
<KLISH>
<PTYPE name="PTYPE1">
<ACTION sym="sym1"\>
</PTYPE>
<VIEW name="view1">
<VIEW name="view1_2">
<COMMAND name="cmd1">
<PARAM name="par1" ptype="/PTYPE1"/>
</COMMAND>
</VIEW>
</VIEW>
<VIEW name="view2">
<VIEW ref="/view1/view1_2"/>
</VIEW>
</KLISH>
The "par1" parameter references PTYPE using the path /PTYPE1. Type names
It is customary to designate types with capital letters to make it easier to distinguish them from other types.
elements. Here the type is defined at the topmost level of the schema. Basic types
are usually defined that way, but PTYPE does not have to be at the top level and
can be nested in VIEW or even PARAM. In this case it will have
a more difficult path.
A VIEW named "view2" imports commands from a VIEW named "view1_2",
Using the path /view1/view1_2.
If, suppose, we need a reference to the parameter "par1", the path will look like this
like this - /view1/view1_2/cmd1/par1.
The following elements cannot be referenced. They do not have a path:
- `KLISH
PLUGINHOTKEYACTION
Do not confuse current session path with the path to create a links. The path uses the internal structure of the schema when creating links, specified when the configuration files are written. This is the path of the element within the schematic, uniquely identifying it. This is a static path. Nesting of elements in defining the schema only generates the necessary instruction sets, this nesting is not visible to the operator and is not a nesting in terms of its work with the command line. It only sees ready-made line sets of commands.
The current session path is dynamic. It is formed by operator commands and implies the possibility to go deeper, i.e. add another level of nesting to the path and access the an additional set of commands, or go higher. With the current path, you can combine the linear paths created at the schematic writing stage. command sets. Navigation commands also allow you to completely replace the current command set to another by changing
VIEWat the current path level. Thus, the existence of the current session path may create visibility for the operator a branching tree of configuration.
Any klish configuration XML file must begin with an opening KLISH tag
and end with a closing tag KLISH.
<?xml version="1.0" encoding="UTF-8"?>
<KLISH
xmlns="https://klish.libcode.org/klish3"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="https://src.libcode.org/pkun/klish/src/master/klish.xsd">
<!-- There's any configuration for klish -->
</KLISH>
The header introduces its default XML namespace "https://klish.libcode.org/klish3". The header is standard and more often than not makes no sense to change it.
On its own, klish does not load any executable function plugins.
Accordingly, no characters are available to the user for use in the
ACTION. Plugin loading should be explicitly written in the files
configurations. The PLUGIN tag is used for this purpose.
Note that even the base plugin named "klish" also fails to load automatically and it must be specified in the configuration files. In this plugin, in In particular, navigation is implemented. A typical configuration will contain a string:
<PLUGIN name="klish"/>
The PLUGIN tag cannot contain other nested tags.
The attribute defines the name by which the plugin will be recognized within the files
configurations. When ACTION refers to a character, it can be specified simply as follows
symbol name, and can be specified in which plugin to look for the symbol.
<ACTION sym="my_sym"\>
<ACTION sym="my_sym@my_plugin"\>
In the first case, klish will search for "my_sym" in all plugins and use the first one found. In the second case the search will be performed only in the plugin "my_plugin". In addition, different plugins may contain the same characters and specifying the plugin will let you know which character was meant.
If the id and file attributes are not specified, name is also used to
formation of the plugin file name. The plugin must have the name kplugin-<name>.so and
is located in the /usr/lib/klish/plugins directory (if klish has been configured with the
with --prefix=/usr).
The attribute is used to form the plugin file name if no attribute is specified
file. The plugin must have the name kplugin-<id>.so and be located in the directory
/usr/lib/klish/plugins (if klish has been configured with
with --prefix=/usr).
If the id attribute is specified, name will not be used to generate the
plugin file name, but only for identification within configuration files.
<PLUGIN name="alias_for_klish" id="klish"\>
<ACTION sym="nav@alias_for_klish"\>
The full name of the plug-in (shared library) file can be specified explicitly
Type. If the file attribute is specified, no other attributes will be specified
will be used to form the plugin file name, and the value of
file "as is" and passed to the dlopen() function. This means that there can be
either an absolute path or just a file name, but in this case the file
must be located along the standard paths used when searching for a shared
libraries.
<PLUGIN name="my_plugin" file="/home/ttt/my_plugin.so"/>
<ACTION sym="my_sym@my_plugin"\>
The data inside the PLUGIN tag can be processed by the initialization function
plugin. The format of the data is left to the discretion of the plugin itself. For example,
settings for the plug-in can be specified as data.
<PLUGIN name="sysrepo">
JuniperLikeShow = y
FirstKeyWithStatement = n
MultiKeysWithStatement = y
Colorize = y
</PLUGIN>
To make it easier to work in the command line interface, for commonly used hotkeys can be set for commands. A hot key is defined with using the `HOTKEY' tag.
Hotkeys require support in the client program to work, which is connects to the klishd server. The klish client has this support.
The HOTKEY tag cannot have nested tags. Any additional data
within the tag are not provided.
The attribute defines what the operator must press to activate the hot
keys. Combinations with the "Ctrl" key are supported. For example ^Z means,
that the "Ctrl" and "Z" key combination must be pressed.
<HOTKEY key="^Z" cmd="exit"\>
The attribute defines what action will be performed when the operator is pressed
hotkey. The cmd attribute value is parsed according to the same rules as
any other command manually entered by the operator.
<COMMAND name="exit" help="Exit view or shell">
<ACTION sym="nav">pop</ACTION>
</COMMAND>
<HOTKEY key="^Z" cmd="exit"\>
The command used as the value of the cmd attribute must be defined
in the configuration files. This example will execute the previously defined command
exit when the "Ctrl^Z" keyboard shortcut is pressed.
The ACTION tag specifies the action to be performed. Typical
tag usage - inside the COMMAND command. When entering an operator
of the corresponding command, the actions defined in ACTION will be executed.
The basic attribute of ACTION is sym. An action can only be performed by
symbols (functions) defined in plugins. The sym attribute refers to such a
symbol.
Actions can be performed by more than just a command. The following is a list of tags,
within which ACTION may occur:
ENTRY- whatACTIONwill be used for is determined by theENTRYparameters.COMMAND- the action defined inACTIONis performed when an operator is entered of the appropriate command.PARAM- same as forCOMMAND.PTYPE-ACTIONdefines actions to check the value of the entered by the operator of the parameter having the corresponding type.
There can be several elements within the listed elements at the same time
ACTION. Let's call it an ACTION element block. Actions are performed
sequentially, one after the other, unless otherwise defined by the exec_on attribute.
Multiple action blocks can be defined within a single command. These are is possible if the command has parameter branching or optional parameters. A block is defined as actions defined within a single element. Actions, defined in different elements, including nested elements, belong to different blocks. Only one block of actions is always performed.
<COMMAND name="cmd1">
<ACTION sym="sym1"\>
<SWITCH min="0">
<COMMAND name="opt1">
<ACTION sym="sym2"\>
</COMMAND>
<COMMAND name="opt2"\>
<PARAM name="opt3" ptype="/STRING">
<ACTION sym="sym3"\>
</PARAM>
</SWITCH>
</COMMAND>
The example declares the command "cmd1", which has three alternatives (specified can be only one of three) optional parameters. The search for actions to be performed goes from end to beginning when parsing the entered command line.
So if the operator entered
command cmd1, the parsing engine will recognize the command named "cmd1" and will
search for ACTION directly in this element. An ACTION with the character
{ "sym1".
If the operator entered the cmd1 opt1 command, the string "opt1" will be recognized,
as a parameter (aka subcommand) named "opt1". The search starts from the end, so
ACTION with the symbol "sym2" will be found first. As soon as the action block is found,
no more actions will be searched and "sym1" will not be found.
If the operator entered the cmd1 opt2 command, the action with the symbol will be found
"sym1", since the "opt2" element has no nested actions of its own and the search
goes upstairs to the parent elements.
If the operator entered the cmd1 arbitrary_string command, an action with the
with the symbol "sym3".
The attribute refers to a symbol (function) from the plugin. This function will be executed when
ACTION execution. The value can be a character name, e.g.
sym="my_sym". In this case, the search for the symbol will be performed over all the
loaded plug-ins. If you specify a plugin in which you want to search for a symbol, e.g.
sym="my_sym@my_plugin", then other plugins will not be searched.
Different situations may benefit from different approaches, relative to the whether to specify a plugin name for the symbol. On the one hand, several plugins can contain characters with the same name and for unambiguous identification symbol, specifying the plugin will be mandatory. In addition, when specifying a plugin the search for a symbol will be a little faster. On the other hand, you could write some universal commands that specify characters without belonging to the plugin. Then multiple plugins can implement an "interface", i.e. all the the symbols used, and their actual content will depend on which plug-in loaded.
Attention: the attribute has not yet been implemented
Some actions require atomicity and exclusive access to the resource. When
This is not automatically ensured when working in klish. Two operators can
independently, but run the same command at the same time. For
ensuring atomicity or/and exclusive access to the resource may
lock locks are used. The locks in klish are named.
The lock attribute specifies the lock with which name the ACTION will capture when the
fulfillment. For example lock="my_lock", where "my_lock" is the name of the lock. Capture
locks with one name have no effect on locks with another name. Thus
Thus, not only one global blocking can be realized in the system, but also
Several separate ones, based, for example, on which resource protects the
lockdown.
If the lock is captured by one process, another process, when attempting to capture the same blockage, will suspend its execution until the release of the lockdowns.
The attribute indicates whether the action can accept data via standard input
(stdin) from the user. Possible values are true, false, tty.
The default value is false.
A value of false means that the action does not accept data through the
standard input. The value true means that the action accepts data through the
standard input. The value tty means that the action accepts data through the
standard input and, in this case, standard input is terminal.
When an action is performed, the client is made aware of the status of the standardized input and, according to it, waits for input from the user or not.
If the command involves sequentially performing several actions at once,
and at least one action has an attribute with the value tty, it is considered that the entire
command has the tty attribute. If there are no actions with the attribute value in the command
tty, then an attribute with the value true is looked for. If any action has
value of the true attribute, then the whole command has the true attribute. Otherwise
case, the command has the false attribute.
If the user has sent not just one command but a chain of commands for execution
(via the | sign), then the following logic applies to notify the client,
whether it is required to receive standard input. If any command in the chain has
value of the tty attribute, then standard input is required. If the first command in
chain has the true attribute, then standard input is required. Otherwise
standard input is not required.
When performing the action, the serving server can create a pseudo-terminal and provide it to the action as a standard input. Will the standard input by a pseudo-terminal or not is determined by whether the standard input on the to the client side by the terminal or not. This information is transmitted from the client to the server in the status word.
The attribute indicates whether the action outputs data via standard output (stdout).
Possible values are true, false, tty.
The default value is true.
A value of false means that the action does not output data through the
standard output. A value of true means that the action outputs data through the
standard output. The value tty means that the action outputs data via the
standard output and, in doing so, the standard output is terminal.
When an action is performed, the client is made aware of the status of the standardized output and, in accordance with it, puts the standard output into the mode raw terminal or not.
Typically, a text client runs a pager on its side to process the output
of each command. If the command attribute has the value tty, the pager does not
is launched. It is assumed that an interactive command is being executed.
If the command involves sequentially performing several actions at once,
and at least one action has an attribute with the value tty, it is considered that the entire
command has the tty attribute. If there are no actions with the attribute value in the command
tty, then an attribute with the value true is looked for. If any action has
value of the true attribute, then the whole command has the true attribute. Otherwise
case, the command has the false attribute.
If the user has sent not just one command but a chain of commands for execution
(via the | sign), then the following logic applies to notify the client of the
status of the standard output. If any command in the chain has
value of the tty attribute, then the "interactivity" flag is passed to the client. В
otherwise the client works as usual.
When performing the action, the serving server can create a pseudo-terminal and
provide its action as a standard output. Will the standard
output by a pseudoterminal or not is determined by whether the standard output is a
on the client side by the terminal and whether the command attribute is set to
tty. Information about whether the standard client-side output is the following
terminal is transmitted from the client to the server in a status word.
The klish system can be run in "dry-run" mode, when all activities are not will actually be executed, and their return code will always have the value of "success". This mode can be used for testing, for checking correctness of incoming data, etc.
However, some characters must always be executed, regardless of mode. An example of such a symbol is the navigation function. I.e. change the current session path is always needed, regardless of the mode of operation.
The permanent flag can change the behavior of a dry-run action.
The possible values of the attribute are true and false. The default is false, i.e.
action is not "permanent" and will be disabled in dry-run mode.
Symbols, when declared in a plugin, already have a persistence feature. Symbol
may be involuntarily declared permanent, involuntarily declared
non-permanent, or the plugin can leave the decision on permanence to the
user. If the persistence flag is declared forcibly in the plugin, then
setting the permanent attribute will not affect anything. It can't
Override the persistence flag enforced within the plugin.
A character can be executed "synchronously" or "asynchronously". In synchronous mode the code symbol will be run directly in the context of the current process - the klishd server. В asynchronous mode, a separate (fork()) will be spawned to run the symbol code. Process. Running the symbol in asynchronous mode is safer, since errors in the code will not affect the klishd process. It is recommended to use asynchronous mode.
The possible values of the attribute are true and false. The default is false, i.e.
symbol will be executed asynchronously.
Symbols, when declared in a plugin, already have a synchronicity feature. Symbol
can be forced to be declared synchronous, asynchronous, or the plugin can
leave the synchronization decision up to the user. If the consistency flag
is declared forcibly in the plugin, then setting the sync attribute will have no effect
on anything. It cannot override the synchronicity flag by forcing a
defined within the plugin.
A single command can contain multiple ACTION elements. This is called
"action block." Each of the actions has its own code
return code. However, the command as a whole must also have a return code and this code is
must be a single value, not an array.
By default, ACTION actions are executed sequentially and as soon as one of the
actions will return an error, block execution will stop and the common return code will be
is considered an error. If no action from the block has returned an error, the following code is used
return code of the last action in the block is considered to be the return code of the last action in the block.
Sometimes it is required that regardless of the return code of a particular action
execution of the block continued. For this purpose the attribute
update_retcode. The attribute can take the value true or false. By
The default is true. This means that the return code of the current action
affects the total return code. At this point, the total return code will be assigned to a
value of the current return code. If the flag value is set to
false, then the current return code is ignored and will have no effect on the
formation of a common return code. Also the execution of the action block will not
interrupted in case of an error at the stage of execution of the current action.
When performing a block of actions (multiple ACTION within one item),
actions are performed sequentially until all actions have been performed,
or until one of the actions returns an error. In this case the block execution
is interrupted. However, this behavior can be controlled by the exec_on attribute.
The attribute can take the following values:
success- the current action will be sent for execution if the value of of the total return code at this point is "success".fail- the current action will be sent to execution if the value of the common return code at this point is "error".always- the current action will be executed regardless of the common code refunds.never- the action will not be performed under any conditions.
The default value is success, i.e. actions are performed if
there were no errors before.
<ACTION sym="printl">1</ACTION>
<ACTION sym="printl" exec_on="never">2</ACTION>
<ACTION sym="printl">3</ACTION>
<ACTION sym="printl" exec_on="fail">4</ACTION>
<ACTION sym="script">/bin/false</ACTION>
<ACTION sym="printl">6</ACTION>
<ACTION sym="printl" exec_on="fail" update_retcode="false">7</ACTION>
<ACTION sym="printl" exec_on="always">8</ACTION>
<ACTION sym="printl" exec_on="fail">9</ACTION>
This example will print to the screen:
1
3
7
8
The string "1" will be printed because at the beginning of the action block execution the common code
return is taken equal to the value "success", as well as the value of exec_on on the
defaults to success.
Line "2" will not be printed because on_exec="never", i.e., do not execute at either
under what conditions.
Line "3" will be executed because the previous action (line "1") was executed successfully.
Line "4" will not execute because the condition on_exec="fail" is present, and with this
the previous action "3" was executed successfully and set the common return code to
the meaning of "success."
Line "5" will execute and set the total return code to "error".
Line "6" will not execute because the current total return code is equal to the value of "error", and the line should only execute if the generic return code is successful.
Line "7" is printed because the condition on_exec="fail" is set, the current generic code is
return is indeed equal to "error". Note that although the action itself
will be executed successfully, the total return code will not be changed, because the used
update_retcode="false" attribute.
Line "8" is printed because the condition on_exec="always" stands for
execute the action regardless of the current total return code.
Line "9" will not be output because line "8" changed the common return code to the meaning of "success."
The data inside the ACTION tag is used at the discretion of the symbol itself,
specified by the sym attribute. An example is the script symbol from the plugin
script. This character uses the data inside the tag as script code that
he must fulfill.
<COMMAND name="ls" help="List root dir">
<ACTION sym="script">
ls /
</ACTION>
</COMMAND>
<COMMAND name="pytest" help="Test for Python script">
<ACTION sym="script">#!/usr/bin/python
import os
print('ENV', os.getenv('KLISH_COMMAND')))
</ACTION>
</COMMAND>
Note that the shebang #!/usr/bin/python is specified in the "pytest" command,
which specifies which interpreter to use to execute the script.
Normally, the
ENTRYtag is not used explicitly in configuration files. However, the tag is the base tag for most other tags and most of its attributes are inherited.
If you look at the internal realization of klish, you can't find the whole set there
tags available when writing an XML configuration. There is actually a basic
ENTRY element, which implements the functions of most other tags. Element
"transforms" into other tags depending on the value of its attributes. The following
tags by internal implementation are the ENTRY element:
In this section, the attributes of the ENTRY element will be discussed in some detail,
which are often attributes of other elements as well. The other elements will be
refer to these descriptions in the ENTRY section. Configuration examples, when describing
attributes, are not necessarily based on the ENTRY element, but use others,
the most typical tags are "wrappers".
The basis of the ENTRY element are the attributes that define the features of its behavior and the
the ability to nest other ENTRY elements inside the ENTRY element. Thus
This is how the entire configuration scheme is built.
The name attribute is the element identifier. Among the elements of the current level
nesting, the identifier must be unique. In different branches of the scheme can
elements with the same name. It is important that the absolute
element path, i.e. a combination of the name of the element itself and the names of all its "ancestors".
For the COMMAND tag, the attribute also serves as a positional parameter value, if not a
attribute value is defined. That is, the operator enters a string equal to the element name
COMMAND to invoke this command.
If the command identifier (name attribute) is different from the command name for a
operator, then the value attribute contains the command name as it is presented
to the operator.
Used for the following tags:
COMMANDPARAMPTYPE<COMMAND name="cmdid" value="next">
In the example, the command identifier is "cmdid". It will be used if
you need to create a reference to this element inside the XML configs. But the user, in order to
run the command to execute it, at the command line enters the text next.
When using the command line, the operator can get a hint on possible
commands, parameters and their purpose. In the klish client the tooltip will be displayed
when the ? key is pressed. The easiest way to set the tooltip text for an element
- is to specify the value of the
helpattribute.
The following tags support the help attribute:
COMMANDPARAMPTYPE
The hint specified with the help attribute is static. The other
The way to specify a hint for an element is to create a nested HELP element.
The HELP element generates the hint text dynamically.
<COMMAND name="simple" help="Command with static help"/>
<COMMAND name="dyn">
<HELP>
<ACTION sym="script">
ls -la "/etc/passwd"
</ACTION>
<HELP>
</COMMAND>
If both the help attribute and the nested element are specified for an element at the same time
HELP, then the dynamic nested element HELP will be used, and the attribute
will be ignored.
The PTYPE element has its own hints. Both static attribute and dynamic attribute
element. These hints will be used for the PARAM parameter using the
this data type, in the case when neither an attribute nor an
HELP dynamic element.
"Container" in klish terms is an element that contains other
elements, but is not visible to the operator. That is, this element is not
is matched to no positional parameters when parsing the entered command line.
lines. It only organizes other elements. Examples of containers are
VIEW, SWITCH, SEQ. The VIEW tag organizes commands in the scope, but
element itself is not a command or parameter for the operator. The operator cannot
enter the name of this item on the command line, it can go straight to the
elements nested in a container (if they are not containers themselves).
The SWITCH and SEQ elements are also not visible to the operator. They define how the
nested elements are processed.
The container attribute can take the values true or false. By default
is used false, i.e. the element is not a container. In this case it is necessary to
note that for all elements - wrappers inherited from ENTRY, the value of
of the attribute is pre-prescribed to the correct value. I.e. use the attribute in
of real configs is usually not necessary. Only in specific cases does it
is really required.
The mode attribute defines how the nested elements will be handled when the
parsing the entered command line. Possible values:
sequence- nested elements will be matched by the entered operator "words" sequentially, one after the other. Thus, all nested elements can take on values when parsed.switch- only one of the nested elements should be matched to the input from the an operator. It is a selection of one out of many. Items that have not been selected are not will get values.empty- an element cannot have nested elements.
So the VIEW element is forced to have the mode="switch" attribute, assuming that the
it contains commands inside it and should not be possible in one line
enter many commands at once one after another. The operator selects at the moment
only one team.
The COMMAND and PARAM elements have a default setting of mode="sequence", so
As most often inside them are placed parameters that must be entered in one
after the other. However, it is possible to override the mode attribute in tags
COMMAND, PARAM.
The SEQ and SWITCH elements are containers and are created only to
change the way nested elements are processed. The SEQ element has
mode="sequence", the SWITCH element has mode="switch".
The following are examples of branching within a command:
<!-- Example 1 -->
<COMMAND name="cmd1">
<PARAM name="param1" ptype="/INT"/>
<PARAM name="param2" ptype="/STRING"/>
</COMMAND>
The command defaults to mod="sequence", so the operator would have to enter
both parameters, one after the other.
<!-- Example 2 -->
<COMMAND name="cmd2" mode="switch">
<PARAM name="param1" ptype="/INT"/>
<PARAM name="param2" ptype="/STRING"/>
</COMMAND>
The value of the mode attribute is overridden, so the operator would have to enter
only one of the parameters. Which of the parameters corresponds to the entered characters
in this case will be determined as follows. First it is checked for
correctness of the first parameter "param1". If the string corresponds to the integer format
numbers, then the parameter takes its value and the second parameter is not checked on the
correspondence, although it would also fit, since the STRING type can contain both the
numbers. Thus, when selecting one parameter out of many, the order of specification is
parameters are important.
<!-- Example 3 -->
<COMMAND name="cmd3">
<SWITCH>
<PARAM name="param1" ptype="/INT"/>
<PARAM name="param2" ptype="/STRING"/>
</SWITCH>
</COMMAND>
This example is identical to example "2". Only instead of the mode attribute the following is used
nested tag SWITCH. The entry in example "2" is shorter, in example "3" it is clearer.
<!-- Example 4 -->
<COMMAND name="cmd4">
<SWITCH>
<PARAM name="param1" ptype="/INT">
<PARAM name="param3" ptype="/STRING">
<PARAM name="param4" ptype="/STRING">
</PARAM>
<PARAM name="param2" ptype="/STRING"/>
</SWITCH>
<PARAM name="param5" ptype="/STRING"/>
</COMMAND>
This demonstrates how command line arguments are parsed. When selected
parameter "param1", then further its nested elements "param3" and
"param4" and then only the SWITCH element following the SWITCH element "param5". Parameter
"param2" is not used in any way.
If "param2" was selected first, then "param5" is processed and the the process is complete.
<!-- Example 5 -->
<COMMAND name="cmd5">
<SWITCH>
<SEQ>
<PARAM name="param1" ptype="/INT">
<PARAM name="param3" ptype="/STRING">
<PARAM name="param4" ptype="/STRING">
</SEQ>
<PARAM name="param2" ptype="/STRING"/>
</SWITCH>
<PARAM name="param5" ptype="/STRING"/>
</COMMAND>
The example is completely similar to the behavior of example "4". Only instead of nesting The `SEQ' tag is used, which says that if the first parameter has been selected. from the sequential parameter block, the other parameters must also be entered as one one after another.
<!-- Example 6 -->
<COMMAND name="cmd6">
<COMMAND name="cmd6_1">
<PARAM name="param3" ptype="/STRING">
</COMMAND>
<PARAM name="param1" ptype="/INT"/>
<PARAM name="param2" ptype="/STRING"/>
</COMMAND>
The example shows a nested "subcommand" named "cmd1_6". Here the subcommand is no different from a parameter, except that the comparison criterion is command line arguments to the `COMMAND' command is to make the entered argument matched the name of the command.
Some nested elements must have a special value. For example, within
VIEW can be defined an element that generates the invitation text for the
operator. To separate the item to generate the prompt from nested commands,
it is necessary to give it a special attribute. Later, when the klishd server should
will get the user prompt for this VIEW, the code will look through the
nested VIEW elements and will select an element that is specifically for this purpose
intended.
The purpose attribute sets the element to a special purpose. Possible
Appointments:
common- there is no special purpose. This is what the normal tags have attribute value.ptype- element defines the type of the parent parameter. TagPTYPE.prompt- the element is used to generate a user prompt for the of the parent element. TagPROMPT. The parent element isVIEW.cond- the element checks the condition and, if it fails, the parent element becomes unavailable to the operator. TagCOND. Not currently implemented.completion- the element generates possible auto-completions for the parent one element. TagCOMPL.help- the element generates a hint for the parent element. TagHELP.
Normally, the purpose attribute is not used directly in configuration files, so
as each special purpose has its own tag, which is more visual.
A schema element can be a reference to another schema element. Creating element "#1", which is a reference to element "#2" is equivalent to the fact that element "#2" will be is declared in the place of the scheme where element "#1" is located. It would be more correct to say, that this is equivalent to creating a copy of element "#2" at the location where the defined element "#1".
If the element is a reference, the ref attribute is defined in the element. The value of the attribute
reference to the target schema element.
<KLISH> <PTYPE name="ptype1"> <ACTION sym="INT"/> </PTYPE> <VIEW name="view1"> <COMMAND name="cmd1"/> </VIEW> <VIEW name="view2"> <VIEW ref="/view1"/> <COMMAND name="cmd2"> <PARAM name="param1" ptype="/ptype1"/> <PARAM name="param2"> <PTYPE ref="/ptype1"/> </PARAM> </COMMAND> </VIEW> <VIEW name="view3"> <COMMAND ref="/view2/cmd2"/> </VIEW> <VIEW name="view4"> <COMMAND name="do"> <VIEW ref="/view1"/> </COMMAND> </VIEW> </KLISH>
In the example, "view2" contains a reference to "view1", which is equivalent to declaring a copy of the "view1" inside "view2." Which in turn means that "cmd1" will become is available in "view2".
Another VIEW named "view3" declares a reference to the command "cmd2". Thus
thus an individual command becomes available inside "view3".
Parameters "param1" and "param2" have the same type /ptype1. Reference to type
can be spelled out using the ptype attribute, or using the nested
tag PTYPE, which is a reference to the previously declared PTYPE. As a result
types of two declared parameters are completely equivalent.
In the last example, the reference to VIEW is enclosed inside the COMMAND tag. In this
In this case it will mean that if we work with "view4", the commands from the
"view1" will be available with the "do" prefix. I.e. if the operator is in
VIEW with the name "view4", then it should write do cmd1 on the command line,
to execute the "cmd1" command.
With the help of references, you can organize code reuse. For example declare a block of "standard" parameters and then use the links to insert them this block into all commands where parameters are repeated.
Suppose the current path consists of several levels. I.e. the operator entered the
nested VIEW. While in the nested VIEW, the operator has access to commands that are not
only of the current VIEW, but also of all parent VIEW. The operator enters the command,
defined in the parent VIEW. The restore attribute determines whether the
changed the current path before executing the command.
The possible values of the restore attribute are true or false. By default
false is used. This means that the command will be executed and the current path will be
will remain the same. If restore="true", before the command is executed, the current
the path will be changed. The nested path levels will be stripped down to the level of that VIEW, in the
where the entered command is defined.
The restore attribute is used in the COMMAND element.
Behavior with recovery of the team's native path can be used in the system, where the configuration mode is implemented according to the principle of routers "Cisco". In this mode, it is not possible to switch to one configuration section. by exiting in advance from another - neighboring section. For this purpose it is necessary to change the current path, rise to the level of the command being entered, and then immediately move to a new section, but already on the basis of the current path corresponding to the the command to enter a new section.
The order attribute determines whether the order is important when entering declared one after another
optional parameters. Suppose three consecutive optional parameters are declared
parameter. The default is order="false" and this means that the operator can
enter these three parameters in any order. Let's say the third one first, then
the first one, followed by the second one. If the order="true" flag is set on the second parameter, then
Having entered the second parameter first, the operator will not be able to enter the first parameter after it.
Only the third parameter will remain available to him.
The order attribute is used in the PARAM element.
Attention: Filters are not working yet.
Some commands are filters. This means that they cannot
to be used independently. Filters only process the output of other commands.
Filters are specified after the main command and the separator character |. Filter
cannot be used before the first | character. In this case, a command that is not
which is a filter cannot be used after the | symbol.
The filter attribute can take the values true or false. By default
filter="false" is used. This means that the command is not a filter.
If filter="true", the command is declared to be a filter.
The filter attribute is rarely used explicitly in configs. The FILTER tag is introduced,
which declares a command that is a filter. In addition to the above limitations on
Using filters, filters are no different from regular commands.
A typical example of a filter is the standard "grep" utility.
The min and max attributes are used in the PARAM element and determine how many
arguments entered by the operator can be matched to the current parameter.
The min attribute specifies the minimum number of arguments that must be
correspond to the parameter, i.e. must pass the correctness check
relative to the data type of this parameter. If min="0", then the parameter
becomes optional. That is, if it is not entered, it is not an error.
The default is min="1".
The max attribute specifies the maximum number of arguments of the same type that are
can be mapped to a parameter. If the operator enters more than
arguments than specified in the max attribute, then these arguments will not be checked
for compliance with the current parameter, but may be checked for compliance with the
other parameters defined after the current one. The default setting is
max="1".
The min="0" attribute can be used in the COMMAND element to declare a
the subcommand is optional.
<PARAM name="param1" ptype="/INT" min="0"/>
<PARAM name="param2" ptype="/INT" min="3" max="3"/>
<PARAM name="param3" ptype="/INT" min="2" max="5"/>
<COMMAND name="subcommand" min="0"/>
In the example, the parameter "param1" is declared optional. Parameter "param2" must correspond to exactly three arguments entered by the operator. Parameter "param3" can correspond from two to five arguments. Subcommand "subcommand" is declared optional.
VIEW are intended for organizing commands and other configuration items in the
"visibility-areas". When the operator works with klish,
the current session path exists. The elements of the path are VIEW elements.
You can change the current path using navigation commands.
If the statement is in a nested VIEW, i.e., the current session path contains the
several levels, like nested directories in a file system, then the operator
all commands belonging not only to VIEW, which is located on the actual
the top level of the path, but also all the "previous" VIEW that make up the path.
You can create "shadow" VIEWs that will never become elements of the current one
paths. TheseVIEWs` can be accessed by links and such a
to add their contents to the place in the schema where the link is created.
VIEW can be defined within the following elements:
- `KLISH
VIEWCOMMANDPARAM
<VIEW name="view1">
<COMMAND name="cmd1"/>
<VIEW name="view1_2">
<COMMAND name="cmd2"/>
</VIEW>
</VIEW>
<VIEW name="view2">
<COMMAND name="cmd3"/>
<VIEW ref="/view1"/>
</VIEW>
<VIEW name="view3">
<COMMAND name="cmd4"/>
<VIEW ref="/view1/view1_2"/>
</VIEW>
<VIEW name="view4">
<COMMAND name="cmd5"/>
</VIEW>
The example demonstrates how scopes work in relation to available scopes to the command operator.
If the current session path is /view1, "cmd1" and "cmd2" are available to the operator.
If the current session path is /view2, the commands "cmd1", "cmd2" are available to the operator,
}, "cmd3".
If the current session path is /view3, "cmd2" and "cmd4" are available to the operator.
If the current session path is /view4, "cmd5" is available to the operator.
If the current session path is /view4/view1, "cmd1" commands are available to the operator,
"cmd2", "cmd5".
If the current session path is /view4/{/view1/view1_2}, the commands available to the operator are
"cmd2", "cmd5". The curly brackets here indicate the fact that the path element
can be any VIEW and it does not matter if it is nested at the
schema definition. Inside the curly braces is the unique path of the element
In the schema. In "Links not elements", explain
the difference between the path that uniquely identifies an element within the schema and the current path
by way of a session.
The COMMAND tag declares a command. Such a command can be executed by an operator.
To map the argument entered by an operator to a command, the following is used
attribute name. If the command identifier is required
within the circuit was different from the name of the command as it appears to the operator,
then name will contain the internal identifier, and the attribute
value "custom" team name. The attributes name and
value can contain only one word, no spaces.
A command is not much different from a PARAM element. A command can
contain subcommands. I.e. another command can be declared within one command
command, which is actually the parameter of the first command, only this one
parameter is identified by a fixed text string.
A typical command contains the help hint or
HELP and, if necessary, a set of nested parameters
PARAM. The command must also specify the actions
ACTION that it performs.
nameis the element identifier.valueis a "custom" command name.help- element description.mode- nested elements processing mode.min- minimum number of command arguments strings mapped to the command name.max- maximum number of command arguments strings matched to the command name.restore- the restore native flag for the team level in the current session path.ref- a reference to anotherCOMMAND.
<PTYPE name="ptype1">
<ACTION sym="INT"/>
</PTYPE>
<VIEW name="view1">
<COMMAND name="cmd1" help="First command">
<PARAM name="param1" ptype="/ptype1"/>
<ACTION sym="sym1"/>
</COMMAND>
<COMMAND name="cmd2">
<HELP>
<ACTION sym="script">
echo "Second command"
</ACTION>
</HELP>
<COMMAND name="cmd2_1" value="sub2" min="0" help="Subcommand">
<PARAM name="param1" ptype="ptype1" help="Par 1"/>
</COMMAND>
<COMMAND ref="/view1/cmd1"/>
<PARAM name="param2" ptype="ptype1" help="Par 2"/>
<ACTION sym="sym2"/>
</COMMAND>
</VIEW>
The command "cmd1" is the simplest version of the command with a hint, one mandatory parameter of type "ptype1" and the action to be performed.
The "cmd2" command is more complex. The hint is generated dynamically. The first
parameter is an optional subcommand with the "custom" name "sub2"
and one mandatory nested parameter. I.e., the operator, wishing to use
subcommand should start its command line this way cmd2 sub2 ....
If the optional "cmd2_1" subcommand is used, the statement must specify
value of its mandatory parameter. The second subcommand is a reference to another subcommand
command. To understand what this would mean, you only have to imagine that on the
this place fully describes the command to which the link points, i.e. "cmd1".
The subcommands are followed by a mandatory numeric parameter and the action to be taken
by the team.
The filter is the COMMAND command with the difference that the command
filtering cannot be used on its own. It only processes the output
other commands and can be used after the main command and the separating
symbol |. For more details on how to use filters, see
"Filters".
For the FILTER tag, the filter attribute is forced to be set to
value true. Other attributes and features of operation coincide with the element
COMMAND.
The PARAM element describes the parameter of the command. The parameter has a type that is specified by
either by the ptype attribute or by the nested element PTYPE. When entering
argument operator, its value is checked by the code of the corresponding PTYPE on the
correctness.
In general, the value for a parameter can be either a string with no spaces, or a string with spaces enclosed in quotation marks.
nameis the element identifier.valueis an arbitrary value that can be analyzed by thePTYPEcode. For theCOMMANDelement, which is a a special case of a parameter, this field is used as the name of a "custom" field teams.help- element description.mode- nested elements processing mode.min- minimum number of command arguments strings matched to the parameter.max- maximum number of command arguments strings matched to the parameter.order- mode of processing optional parameters.ref- a reference to anotherCOMMAND.ptype- reference to the type of the parameter.
<PTYPE name="ptype1">
<ACTION sym="INT"/>
</PTYPE>
<VIEW name="view1">
<COMMAND name="cmd1" help="First command">
<PARAM name="param1" ptype="/ptype1" help="Param 1"/>
<PARAM name="param2" help="Param 2">
<PTYPE ref="/ptype1"/>
</PARAM>
<PARAM name="param3" help="Param 3">
<PTYPE>
<ACTION sym="INT"/>
</PTYPE>
</PARAM>
<PARAM name="param4" ptype="/ptype1" help="Param 4">
<PARAM name="param5" ptype="/ptype1" help="Param 5"/>
</PARAM>
<ACTION sym="sym1"/>
</COMMAND>
</VIEW>
Parameters "param1", "param2", "param3" are identical. In the first case the type is set
by the ptype attribute. In the second, the nested PTYPE element, which is the
reference to the same type "ptype1". In the third one, the type of the parameter is determined by
"in place", i.e. a new type PTYPE is created. But in all three cases the type
is an integer (see the sym attribute). Specify the type directly inside the parameter
can be handy if this type is not needed anywhere else.
The parameter "param4" has a nested parameter "param5". After entering the argument for parameter "param4", the operator will have to enter the argument for the nested parameter.
The SWITCH element is a container. Its only
task is to set the processing mode of nested elements. SWITCH specifies
such a mode of processing of nested elements, when from many must be selected
only one element.
In the SWITCH element, the mode attribute is forced to be set to
switch value.
For more information about the processing modes of nested elements, see the section
"Attribute mode".
Normally, the SWITCH element is used without attributes.
<COMMAND name="cmd1" help="First command">
<SWITCH>
<COMMAND name="sub1"/>
<COMMAND name="sub2"/>
<COMMAND name="sub3"/>
</SWITCH>
</COMMAND>
By default, the COMMAND element has the mode="sequence" attribute. If the
example did not have a SWITCH element, then the statement should have been sequential,
set all subcommands one by one: cmd1 sub1 sub2 sub3. The SWITCH element
changed the processing mode of nested elements and as a result the operator must select
only one subcommand out of three. For example cmd1 sub2.
The SEQ element is a container. Its only
task is to set the processing mode of nested elements. SEQ specifies
such a mode of processing nested elements, when all nested elements must be
to be set one after the other.
In the SEQ element, the mode attribute is forced to be set to
sequence value.
For more information about the processing modes of nested elements, see the section
"Attribute mode".
Normally, the SEQ element is used without attributes.
<VIEW name="view1">
<SEQ>
<PARAM name="param1" ptype="/ptype1"/>
<PARAM name="param2" ptype="/ptype1"/>
<PARAM name="param3" ptype="/ptype1"/>
</SEQ>
</VIEW>
<VIEW name="view2">
<COMMAND name="cmd1" help="First command">
<VIEW ref="/view1">
</COMMAND>
</VIEW>
Suppose we have created an auxiliary VIEW containing a list of frequently
parameters used and called it "view1". All parameters must
to be used sequentially, one after the other. And then in another VIEW declared.
command, which must contain all these parameters. To do this, inside the command
a reference to "view1" is created and all parameters "fall" inside the command. However
the VIEW element has the mode="switch" attribute by default and it turns out that
operator will not enter all declared parameters, but must select only
one of them. To change the order in which nested parameters are parsed, use
element SEQ. It changes the order of parameter parsing to sequential.
The same result could be achieved by adding the mode="sequence" attribute to the
"view1" declaration. Attribute usage - shorter, element usage
`SEQ' is more descriptive.
The PTYPE element describes the data type for the parameters. Parameters
PARAM refer to a data type using the ptype attribute or
contain a nested PTYPE element. The task of PTYPE is to check the passed
operator argument for correctness and return the result as "success" or
"error." More precisely, the result of the test can be expressed as
"fits' ordoesn't fit'. Within the PTYPE element the actions are specified
ACTION, which performs the argument check against the
of the declared data type.
<PTYPE name="ptype1" help="Integer">
<ACTION sym="INT"/>
</PTYPE>
<PARAM name="param1" ptype="/ptype1" help="Param 1"/>
The example declares the data type "ptype1". This is an integer and the INT character from the
The standard plugin "klish" checks that the entered argument is valid.
is an integer.
Other uses of the PTYPE tag and the ptype attribute are discussed in the
PARAM element example section.
The PROMPT element has a special purpose and is nested to the element
VIEW. The purpose of the element is to form a prompt for the user if
parent VIEW is the current path of the session. If the current path
multilevel, then failing to find a PROMPT element in the last element of the path,
the search engine will go up a level and search for PROMPT there. And so
down to the root element. If PROMPT is not found there, then
standard invitation is used at the discretion of the klish client. By default
klish client uses the $ prompt.
Within the PROMPT element, the ACTION actions are specified, which are
form the invitation text for the user.
The PROMPT element is forcibly assigned the value of the purpose="prompt" attribute.
Also, PROMPT is a container.
Normally, PROMPT is used without attributes.
<VIEW name="main">
<PROMPT>
<ACTION sym="prompt">%u@%h> </ACTION>
</PROMPT>
</VIEW>
In the example for VIEW named "main", which is the current path on the
The default when starting klish, the user prompt is defined. IN ACTION.
The prompt symbol from the standard "klish" plugin is used, which helps to
in forming the invitation, replacing the %u or %h constructs with substitutions.
Specifically %u is replaced by the current user name and %h is replaced by the host name.
The HELP element has a special purpose and is nested for elements
COMMAND, PARAM, PTYPE. The purpose of the element is to form text
"help, i.e. a hint for the parent element. Inside the HELP element
specifies the ACTION actions that form the tooltip text.
The HELP element is forcibly assigned the value of the purpose="help" attribute.
Also HELP is a container.
The klish client shows hints on pressing the ? key.
Normally, HELP is used without attributes.
<PARAM name="param1" ptype="/ptype1">
<HELP>
<ACTION sym="sym1"/>
</HELP>
</PARAM>
The COMPL element has a special purpose and is nested for elements
PARAM, PTYPE. The purpose of the element is to form auto-complete variants,
i.e. possible variants of values for the parent element. Within an element
COMPL specifies the ACTION actions that generate the output.
The individual variants in the output are separated from each other by a line feed.
The COMPL element is forcibly assigned the attribute value
purpose="completion". Also COMPL is a container.
The klish client shows autocomplete options when the Tab key is pressed.
<PARAM name="proto" ptype="/STRING" help="Protocol">
<COMPL>
<ACTION sym="printl">tcp</ACTION>
<ACTION sym="printl">udp</ACTION>
<ACTION sym="printl">icmp</ACTION>
</COMPL>
</PARAM>
The parameter specifying the protocol is of type /STRING, i.e. an arbitrary string.
The operator can enter arbitrary text, but for convenience the parameter has a
autocomplete options.
The functionality of the
CONDelement has not yet been implemented.
The COND element has a special purpose and is nested for elements
VIEW, COMMAND, PARAM. The purpose of the element is to hide the element from the operator in the
if the condition specified in COND is not met. Within an element
COND specifies the ACTION actions that check the condition.
The COND element is forcibly assigned the value of the attribute
purpose="cond". Also COND is a container.
<COMMAND name="cmd1" help="Command 1">
<COND>
<ACTION sym="script">
test -e /tmp/cond_file
</ACTION>
</COND>
</COMMAND>
If the /tmp/cond_file file exists, the "cmd1" command is available to the operator,
if it does not exist, the command is hidden.
The klish source tree includes the code for the standard "klish" plugin. The plugin contains basic data types, navigation command and other auxiliary data types characters. In the vast majority of cases, this plugin should be used. However, it is not automatically connected because in some rare specific you may need to be able to work without it.
The standard way to connect the "klish" plugin is in the configuration files:
<PLUGIN name="klish"/>
The plugin comes with the ptypes.xml file, where the basic data types are declared in the
as PTYPE elements. Declared data types use the characters
plugin to check if the argument matches the data type.
All section characters are intended to be used in PTYPE elements if
unless otherwise specified, and check that the entered argument matches the data type.
The COMMAND character verifies that the entered argument matches the command name.
That is, with the name or value attributes of the COMMAND or PARAM elements. If
attribute value is set, then its value is used as the command name.
If not specified, the value of the name attribute is used. Character case in
the team name doesn't count.
The completion_COMMAND symbol is for the COMPL element nested in the
PTYPE. The character is used to generate an autocomplete string for the
team. The autocomplete for a team is the name of the team itself. If
attribute value is set, then its value is used as the command name.
If not specified, the value of the name attribute is used.
The help_COMMAND symbol is for a HELP element nested in a
PTYPE. The character is used to form a description (help) string for the
commands. If the value attribute is specified, its value is used as a
of the command name. If not specified, the value of the name attribute is used. В
the value of the help attribute of the command is used as the hint itself.
The COMMAND_CASE symbol is completely analogous to the COMMAND symbol,
except that it takes into account the case of the characters in the command name.
The INT character verifies that the entered argument is an integer.
The digit capacity of the number corresponds to the long long int type in the C language.
Within the ACTION element, a valid range can be defined for the
integer. Specifies the minimum and maximum values, separated by the
with a space.
<ACTION sym="INT">-30 80</ACTION>
The number can take values between "-30" and "80".
The UINT character verifies that the entered argument is an unsigned integer
number. The digit capacity of the number corresponds to the unsigned long long int type in the C language.
Within the ACTION element, a valid range can be defined for the
numbers. The minimum and maximum values are specified, separated by a space.
<ACTION sym="UINT">30 80</ACTION>
The number can take values between "30" and "80".
The STRING character checks that the entered argument is a string. Now there is no
no specific string requirements.
Using navigation commands, the operator changes the current path of the session.
The nav symbol is used for navigation. The nav subcommands can be used to
change the current session path. All subcommands of the nav symbol are specified internally
of the ACTION element - each command on a separate line.
Subcommands of the symbol nav:
push <view>- enter the specifiedVIEW. To the current session path is added another level of nesting.pop [num]- go to the specified number of nesting levels. I.e. exclude from the current session pathnumof the upper levels. Thenumargument is optional. The default isnum=1. If we are already in the rootVIEW, i.e. the current path contains only one level, thenpopwill end the session and exit the klish.top- go to the root level of the current session path. I.e. exit from all nestedVIEW.replace <view>- replaceVIEW, which is at the current nesting level to the specifiedVIEW. The number of nesting levels is not increased. Changes only the very last component of the path.exit- end the session and exit klish.<ACTION sym="nav"> pop push /view_name1 </ACTION>
The example shows how you can repeat the replace subcommand using other
subcommands.
Empty command. The symbol does nothing. Always returns the value
0 is "success".
Prints the text specified in the body of the ACTION element. At the end of the text, the translation
of the string is not output.
<ACTION sym="print">Text to print</ACTION>
Prints the text specified in the body of the ACTION element. At the end of the text is added
string translation.
<ACTION sym="printl">Text to print</ACTION>
Prints the current path of the session. Needed mainly for debugging.
The prompt symbol helps to generate the invitation text for the operator. In the body
the ACTION element specifies the text of the invitation, which may contain
substitutions of the form %s, where "s" is some printed character. Instead of this
A certain string is substituted into the text. List of implemented
substitutions:
%%is the%symbol itself.%his the hostname.%uis the name of the current user.<ACTION sym="prompt">%u@%h> </ACTION>
The "script" plugin contains only one script character and is used to execute the
scripts. The script is contained in the body of the ACTION element. A script can be written
in different scripting programming languages. By default, a script is assumed to be
is written for the shell interpreter and is run with /bin/sh. To
to choose a different interpreter, shebang is used. Shebang is
text of the form #!/path/to/binary located in the very first line of the script.
The text /path/to/binary is the path where the script interpreter is located.
The script plugin is included in the source code of the klish project, and it is possible to connect the
plug-in can be used as follows:
<PLUGIN name="script"/>
The name of the command to be executed and the parameter values are passed to the script using environment variables. The following environment variables are supported:
KLISH_COMMAND- name of the command to be executed.KLISH_PARAM_<name>- value of the parameter named<name>.KLISH_PARAM_<name>_<index>- one parameter can have many values if attributemaxis set for it and the value of this attribute is greater than one. Then values can be obtained by index.
Examples:
<COMMAND name="ls" help="List path">
<PARAM name="path" ptype="/STRING" help="Path"/>
<ACTION sym="script">
echo "$KLISH_COMMAND"
ls "$KLISH_PARAM_path"
</ACTION>
</COMMAND>
<COMMAND name="pytest" help="Test for Python script">
<ACTION sym="script">#!/usr/bin/python
import os
print('ENV', os.getenv('KLISH_COMMAND')))
</ACTION>
</COMMAND>
The "ls" command uses the shell interpreter and displays a list of files by to the path specified in the "path" parameter. Note that using shell may not be safe, due to the potential for the operator to introduce into the script arbitrary text and, accordingly, execute an arbitrary command. The use of shell is available but not recommended. It is very difficult to write a secure shell script.
The "pytest" command executes a Python script. Note where
shebang is defined. The first line of the script is the line that is located
immediately following the ACTION element. A line following a line in which
declared ACTION is considered to be the second one and it is not allowed to define shebang in it.
The "lua" plugin contains just one lua character and is used to execute the
scripts in the Lua language. The script is contained in the body of the ACTION element. Unlike
from the script character from the "script" plugin, the lua character does not
calls an external interpreter program to execute scripts, and uses a
internal mechanisms for doing so.
The lua plugin is included in the source code of the klish project, and to plug in the
plug-in can be used as follows:
<PLUGIN name="lua"/>
The contents of the tag can specify the configuration.
Let's take a look at the plugin configuration parameters.
autostart="/usr/share/lua/klish/autostart.lua"
When the plugin is initialized, it creates a Lua machine state that (after fork)
and will be used to call the Lua ACTION code. If it is necessary to load
It can be done by setting autostart file. Parameter
there can only be one.
package.path="/usr/lib/lua/clish/?.lua;/usr/lib/lua/?.lua".
Specifies the Lua package.path (the paths used to search for modules). The parameter can there can only be one.
backtrace=1
Whether to show backtrace when Lua code crashes. 0 or 1.
When Lua ACTION is executed, the following functions are available:
Returns information about the parameters. There are two possible uses for this functions.
local pars = klish.pars()
for k, v in ipairs(pars) do
for i, p in ipairs(pars[v]) do
print(string.format("%s[%d] = %s", v, i, p))
end
end
Obtaining information about all parameters. In this case the function is called without arguments and returns a table of all parameters. The table contains a list of names, as well as an array of values for each name. The example above shows an iterator for all parameters with their values displayed.
In addition, klish.pars can be called to take the values of a particular parameter, e.g.:
print("int_val = ", klish.pars('int_val')[1]))
Works exactly the same as klish.ppars(), but only for the parent ones
parameters, if there are any in this context.
Work the same as klish.pars(), klish.ppars() with the assignment of a specific
parameters, but return a value rather than an array. If parameters with this name
a few, the first one will come back.
Returns the current path as an array of strings. For example:
print(table.concat(klish.path(), "/"))
Allows to get some parameters of the command context. Takes as input string -- the name of the context parameter:
- val;
- cmd;
- pcmd;
- uid;
- pid;
- user.
Without parameter, returns a table with all available context parameters.